
Copy on Write란?
Copy on Write는 원본이나 복사본에서의 실제 값 변경이 발생하기 전까지는 같은 값을 가리키고 있다가 실제 값 변경 발생 시 복사를 수행하는 방식으로 Swift는 Collection Type( Array, Set, Dictionary )과 String Type에서 CoW 복사 방식을 사용합니다.
왜 사용해야 하나요?
Swift에서는 Value Type의 복사는 깊은 복사 방식을 사용하는데 Collection Type 같은 경우는 Value Type이지만 heap 영역에 생성되어 매번 깊은 복사 방식을 사용하면 높은 메모리 오버헤드를 발생시킬 수 있다.
이를 방지하기 위해 Collection Type의 경우 복사한 데이터의 수정이 발생하지 않는다면 얕은 복사와 같이 heap영역에 생성된 데이터의 주소값만 공유하고 있다가 값의 변경이 발생했을 때 깊은 복사를 사용하는 방식을 채택하여 메모리를 효율적으로 관리할 수 있다.
깊은 복사란?
Swift에서 Value Type 복사 시 사용하는 방법으로 데이터 자체를 복사하여 독립적인 메모리 공간을 차지하게 하여 복사본을 수정하여도 원본에는 영향이 가지 않습니다.
얕은 복사란?
Swift에서 Reference Type 복사 시 사용하는 방법으로 가리키고 있는 인스턴스의 주소값만 공유하여 같은 인스턴스를 가리키게 하는 방식으로 복사본 수정 시 원본 데이터에도 영향이 가므로 주의가 필요합니다.
Copy on Write 동작 방식
var arr1: [Int] = [1]
var arr2: [Int] = arr1
arr2.append(2)1. 힙영역에 1을 값으로 가지고 있는 배열을 생성합니다.
2. arr2에 arr1이 가리키고 있는 배열의 참조를 복사합니다.
3. 복사본인 arr2에 값의 변화가 발생하였으므로 arr2에 2라는 값을 더하기 전에 힙영역에서 배열의 복사를 수행합니다.
4. 복사한 배열에 2라는 값을 더해주고 arr2가 원본 배열이 아닌 복사한 배열을 가리키게 합니다.
실제 메모리 주소 확인해 보기
메모리 주소를 출력하는 함수
func print(address o: UnsafeRawPointer) {
print(String(format: "%p", Int(bitPattern: o)))
}
배열에서 CoW의 동작을 테스트 해보기 위한 함수
func arrayMemoryTest() {
var arr1 = [1]
var arr2 = arr1
print(address: arr1)
print(address: arr2)
print("[arr2에 2추가]")
arr2.append(2)
print(address: arr1)
print(address: arr2)
print("[Fin]")
}위의 함수를 그냥 실행시키면 다음과 같은 출력 결과를 얻을 수 있다

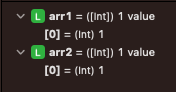
49번째 라인에서 break point를 걸어 메모리 주소를 확인해 보면
| arr1 & arr2 배열 | arr1의 메모리 | arr2의 메모리 |
 |
 |
 |
arr1의 메모리와 arr2의 메모리가 같은 내용을 담고 있음을 확인할 수 있다.
| arr1 & arr2 배열 | arr1의 메모리 | arr2의 메모리 |
 |
 |
 |
다시 55번째 라인에서 break point를 걸어 다시 메모리를 확인해 보면 arr2의 메모리에 변화가 생겼음을 알 수 있다.
즉 실제 배열의 값 변경이 발생하고 나서야 메모리의 변화가 생겼음을 알 수 있다.
혹시 40 11 5C 03 00 60 00 ... 와 같은 구조가 사실은 같은 깊은 복사가 일어났고 [1]이라는 같은 값을 가진 배열을 가리키고 있어서 똑같이 나온 게 아닐까 하는 의구심에 새로운 변수에 [1] 배열을 담고 메모리를 확인해 보았더니 다행히 아니었다.


String에서 CoW 동작을 테스트 해보기 위한 함수
우선 String Type은 문자열 할당시 스택 영역에 16바이트가 할당됨과 동시에 힙 영역인 MALLOC_TINY 영역에 내부 문자열 공간이 할당된다고 한다.
func stringMemoryTest() {
var str1 = "ab"
str1 += "abc"
var str2 = str1
str2 += "abcd"
}이번에는 위 함수를 lldb을 통해 디버깅하여 확인해 보도록 하겠다.
var str1 = "ab"
// (lldb) p str1._guts._object.nativeUTF8Start
// (UnsafePointer<UInt8>) $R0 = 0x200000000000020 {}str1에 "ab"를 할당한 후 str1이 버퍼 0x200000000000020를 가리키고 있다.
str1 += "abc"
// (lldb) p str1._guts._object.nativeUTF8Start
// (UnsafePointer<UInt8>) $R1 = 0x500000000000020 {}str1에 "abc"를 더하니 버퍼 0x500000000000020를 가리키고 있다.
var str2 = str1
// (lldb) p str1._guts._object.nativeUTF8Start
// (UnsafePointer<UInt8>) $R2 = 0x500000000000020 {}
// (lldb) p str2._guts._object.nativeUTF8Start
// (UnsafePointer<UInt8>) $R3 = 0x500000000000020 {}str2에 str1을 할당한 후 str1과 str2 둘 다 같은 버퍼 0x500000000000020를 가리키고 있다.
str2 += "abcd"
// (lldb) p str1._guts._object.nativeUTF8Start
// (UnsafePointer<UInt8>) $R4 = 0x500000000000020 {}
// (lldb) p str2._guts._object.nativeUTF8Start
// (UnsafePointer<UInt8>) $R5 = 0x900000000000084 {}str2에 "abcd"를 더해주니 str1은 여전히 버퍼 0x500000000000020를 가리키고 있지만 str2는 기존에 가리키고 있던 버퍼가 아닌 새로운 버퍼 0x900000000000084를 가리키게 되어 이를 통해 String Type에서도 CoW가 동작함을 알 수 있다.
또한 document에서도 String Type은 CoW를 지원함을 확인할 수 있다.

*추가적으로 짧은 문자열일 경우 Heap영역 뿐만 아니라 Stack영역에도 직접 저장시킨다고 하며 아래 테스트 결과에서도 확인가능하다.

결론
값 타입임에도 불구하고 컴파일 타임에 정확한 사이즈를 알기 어려운 가변 길이를 가진 Collection Type과 String Type은 Heap에 데이터를 저장하여 사용하기 때문에 매번 깊은 복사를 사용하기에는 높은 메모리 오버헤드가 발생할 수 있다 따라서 Copy on Write를 통해 데이터의 변화가 발생하기 전까지는 얕은 복사처럼 동작하다 원본이나 복사본의 변화가 생기면 깊은 복사를 수행하여 메모리를 효율적으로 사용할 수 있다.
'iOS > Swift' 카테고리의 다른 글
| [Swift] 문자열은 무엇으로 구성되어 있을까? - Extended Grapheme Clusters (0) | 2023.02.18 |
|---|---|
| [Swift] Convenience initializer 알아보기 (0) | 2023.02.16 |
| [Swift] Class의 성능을 향상 시킬수 있는 방법 :: Static Dispatch (0) | 2023.02.09 |
| [Swift] Class, Struct, Enum의 차이점을 알아보자 (0) | 2023.02.09 |
| [Swift] 매우 간단하게 함수의 성능을 개선하기(메모리 관리) (0) | 2023.01.30 |